スプレッドシートで「@マークは何文字目にある?」「スラッシュの位置を調べたい」と思ったことはありませんか?文字列から特定の文字の位置を手作業で数えるのは面倒ですし、データが何百行もあると現実的ではないですよね。
FIND関数を使えば、特定の文字が何文字目にあるかを一発で調べられます。この記事ではスプレッドシートでのFIND関数の基本から、LEFT・MID関数との組み合わせ応用、エラー対処法まで丁寧に解説します。
FIND関数とは?スプレッドシートで文字の位置を検索する関数
FIND関数は、文字列の中から特定の文字が何文字目にあるかを返す関数です。読み方は「ファインド」。英語の「Find(見つける)」がそのまま名前になっています。
たとえば「tanaka@example.com」の中で「@」は7文字目にあります。FIND関数はこの「7」という数値を返してくれます。
最大の特徴は大文字と小文字を区別することです。「A」と「a」を別の文字として扱います。区別しない検索にはSEARCH関数を使います。この違いについては後ほど詳しく解説しますね。
FIND関数の書き方(構文と引数)
基本構文
=FIND(検索文字列, テキスト, [開始位置])| 引数 | 必須/省略可 | 説明 |
|---|---|---|
| 検索文字列 | 必須 | 探したい文字または文字列 |
| テキスト | 必須 | 検索対象のセルまたはテキスト |
| 開始位置 | 省略可 | 何文字目から検索を始めるか(省略時は1) |
戻り値は「検索文字列が最初に見つかった位置」の数値です。1文字目が「1」なので、0始まりではありません。
第3引数(開始位置)の使いどころ
開始位置を指定すると、途中から検索を開始できます。同じ文字が複数回出てくるテキストで「2番目の出現位置」を調べたいときに使います。
=FIND("-", "ABC-001-RED") → 4(最初のハイフン)
=FIND("-", "ABC-001-RED", 5) → 8(2番目のハイフン)1回目のFINDで最初のハイフン位置(4)を取得し、その次の位置(5)から検索を再開する仕組みです。MID関数との組み合わせで区切り文字間の文字を取り出すときに活躍しますよ。
基本的な使い方
セルA2に「tanaka@example.com」が入っているとします。
=FIND("@", A2) → 7(@は7文字目)
=FIND("example", A2) → 8("example"は8文字目から始まる)
=FIND("a", A2) → 2(最初の小文字"a"は2文字目)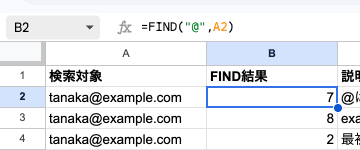

検索文字列は1文字でも複数文字でもOKです。複数文字の場合は先頭文字の位置を返します。
大文字小文字を区別するので、=FIND("T", A2) は「T」が存在しないため#VALUE!エラーになります。先頭は小文字の「t」だからです。
FIND関数とSEARCH関数の違い
スプレッドシートには文字位置を調べる関数が2つあります。FINDとSEARCHです。用途に合わせて使い分けましょう。
比較表
| 項目 | FIND | SEARCH |
|---|---|---|
| 大文字/小文字 | 区別する | 区別しない |
| ワイルドカード | 使えない | *(任意の文字列)?(任意の1文字)が使える |
| 用途 | 完全一致で正確に検索 | あいまい検索・大文字小文字を気にしない場合 |
| 構文 | =FIND(検索文字列, テキスト, [開始位置]) | =SEARCH(検索文字列, テキスト, [開始位置]) |
どちらを使うか迷ったときの判断基準
使い分けのポイントはシンプルです。
- 大文字小文字を区別したい → FIND
- 区別しなくてよい → SEARCH
- ワイルドカードで曖昧検索したい → SEARCH
実務では「@」「/」「-」のような記号の位置を調べる場面が多いです。記号には大文字小文字がないので、FINDでもSEARCHでも同じ結果になります。どちらを使っても大丈夫ですよ。
一方、「CSV」と「csv」を区別して検索したい場面ではFIND一択です。
実務での活用例(LEFT・MID・RIGHTとの組み合わせ)
FIND関数の真価は、他の文字列関数と組み合わせたときに発揮されます。FIND関数で「位置」を調べて、LEFT関数やMID関数で「文字を取り出す」のが定番パターンです。
メールアドレスの@より前を取り出す(LEFT + FIND)
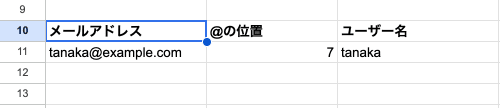
A2に「tanaka@example.com」が入っています。@より前の「tanaka」を取り出してみましょう。
=LEFT(A2, FIND("@", A2)-1) → 「tanaka」分解して見ていきます。
FIND("@", A2)→ @は7文字目- 7 – 1 = 6(@の直前の位置)
LEFT(A2, 6)→ 先頭から6文字で「tanaka」
FINDで位置を調べて、LEFTの文字数に渡すだけです。メールアドレスの長さが人ごとに違っても正しく取り出せますよ。
スラッシュ区切りの日付から年月日を分離する(MID + FIND)
A2に「2024/03/18」が入っています。年・月・日をそれぞれ取り出してみましょう。
年: =LEFT(A2, FIND("/", A2)-1) → 「2024」
月: =MID(A2, FIND("/", A2)+1, FIND("/", A2, FIND("/", A2)+1)-FIND("/", A2)-1) → 「03」
日: =MID(A2, FIND("/", A2, FIND("/", A2)+1)+1, LEN(A2)) → 「18」ちょっとむずかしく見えますが、やっていることはシンプルです。
- 年: 最初の「/」より前をLEFTで取得
- 月: 1番目の「/」と2番目の「/」の間をMIDで取得
- 日: 2番目の「/」より後ろをMIDで取得
2番目の「/」を見つけるには、FIND関数の第3引数を使います。FIND("/", A2, FIND("/", A2)+1) で「1番目の/の次の位置から検索」を実行しています。

ファイル名から拡張子を取り出す(RIGHT + LEN + FIND)
A2に「report.pdf」が入っています。ピリオド以降の「pdf」を取り出す例です。
=RIGHT(A2, LEN(A2)-FIND(".", A2)) → 「pdf」FIND(".", A2)→ ピリオドは7文字目LEN(A2)→ 全体は10文字- 10 – 7 = 3
RIGHT(A2, 3)→ 末尾3文字で「pdf」
RIGHT関数とLEN関数(文字列全体の文字数を返す関数)を組み合わせると「特定の文字より後ろ全部」を取得できます。拡張子が「xlsx」のように4文字でも正しく動きますよ。
エラー(#VALUE!)の原因と対処法
FIND関数で最も多いのが#VALUE!エラーです。原因は大きく2つあります。
エラーの原因
| 原因 | 例 | 説明 |
|---|---|---|
| 検索文字列が見つからない | =FIND("@", "tanaka") | テキストに@が存在しない |
| 開始位置がテキスト長を超えている | =FIND("a", "abc", 10) | 3文字しかないのに10文字目から検索 |
大文字小文字を区別するFINDでは、「A」を検索しているのにテキスト内には「a」しかない場合もエラーになります。意図しないエラーの原因になりやすいので注意してください。
IFERRORで安全に処理する
検索対象が見つからないケースを想定して、IFERRORでラップするのが実務の定番です。
=IFERROR(FIND("@", A2), 0)@が見つかればその位置を、見つからなければ0を返します。
LEFT関数との組み合わせでも同じパターンが使えます。
=IFERROR(LEFT(A2, FIND("@", A2)-1), "メールアドレスではありません")実務データは書式がバラバラなことも多いです。FIND関数を使うときはIFERRORとセットで覚えておくと安心ですよ。

まとめ
FIND関数の要点を整理します。
| ポイント | 内容 |
|---|---|
| 基本構文 | =FIND(検索文字列, テキスト, [開始位置]) |
| 戻り値 | 検索文字列が最初に見つかった位置(1始まり) |
| 大文字/小文字 | 区別する(SEARCHは区別しない) |
| ワイルドカード | 使えない(SEARCHは使える) |
| 見つからない場合 | #VALUE!エラー(IFERRORで対処) |
| 開始位置省略 | 先頭(1文字目)から検索 |
FIND関数は単体では「位置を調べる」だけの関数です。でもLEFT関数・MID関数・RIGHT関数と組み合わせると、文字列を自在に分割できる強力なツールになります。
まずは「@の位置を調べる」「/の位置を調べる」というシンプルな使い方から試してみてください。慣れてきたらLEFT+FINDやMID+FINDの組み合わせに挑戦して、文字列操作の幅を広げていきましょう。
