スプレッドシートで誤差関数を扱おうとして、ERF と ERF.PRECISE の2つが並んでいて「どっちを使えばいいの?」と手が止まったことはありませんか。名前に「PRECISE(精密)」と付いているので「こっちの方が高精度なのかな?」と思ってしまいますが、実はその理解はズレています。
結論から言うと、ERF.PRECISE は「ERFよりも精度が高い関数」ではなく、「引数を1つに絞ったシンプル版のERF」です。Excel 2010で命名規則を整理した際に追加された関数で、Googleスプレッドシートでもそのまま使えます。
この記事では、ERF.PRECISE 関数の構文・使い方・ERF との違いを、実際のスプレッドシートでの入力例とともに整理します。誤差関数ファミリー4関数(ERF / ERF.PRECISE / ERFC / ERFC.PRECISE)の比較表も用意しました。「結局どれを使えばいいの?」という疑問もこの1記事で解消できます。なお、ERF 関数の基本については スプレッドシートのERF関数の使い方|誤差関数(Error Function)を解説 で詳しく解説しているので、合わせてご覧ください。
ERF.PRECISE関数とは
ERF.PRECISE 関数は、Googleスプレッドシートのエンジニアリング関数カテゴリに属する関数です。ガウスの誤差関数(error function)を計算し、引数として渡した上限値 x までの誤差関数の値を返します。
数学的に書くと、誤差関数の定義は以下のとおりです。
erf(x) = (2/√π) × ∫₀ˣ e^(-t²) dt積分の下限が「0」に固定されており、上限が引数 x のみという点が ERF.PRECISE の最大の特徴です。戻り値の範囲は -1〜1 で、x が大きくなるほど 1 に漸近します。
ERF.PRECISEの構文と引数
構文はシンプルです。引数は1つだけです。
=ERF.PRECISE(x)| 引数 | 内容 | 必須 |
|---|---|---|
| x | 誤差関数を計算する上限値(数値) | 必須 |
x には数値リテラル(例: 1)か、数値が入ったセル参照(例: A2)を渡します。文字列や空白を渡すと #VALUE! エラーになります。
関数が返す値の意味
戻り値は「0から x までの区間における、ガウス曲線下の面積を正規化した値」です。いくつかサンプルを並べると数値感がつかみやすくなります。
x の値 | =ERF.PRECISE(x) の戻り値 |
|---|---|
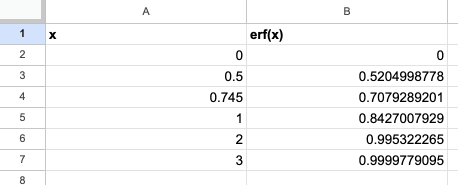
| 0 | 0 |
| 0.5 | 約 0.5204998778 |
| 0.745 | 約 0.7079289200 |
| 1 | 約 0.8427007929 |
| 2 | 約 0.9953222650 |
| 3 | 約 0.9999779095 |
x が 2 を超えると戻り値はほぼ 1 に張り付きます。「ある値より外側に出る確率はほぼゼロ」という統計的な意味を持ち、品質管理の不良率計算などで活躍します。
ERF.PRECISE関数の基本的な使い方
ここからは実際にスプレッドシートで入力する例を見ていきます。引数が1つの関数なので、迷うポイントはほぼありません。
セルへの入力例
いちばんシンプルな使い方は、数値を直接書き込むパターンです。
=ERF.PRECISE(1)このセルには 0.8427007929 が表示されます。「erf(1) の値」です。
数値を直接入力する場合
特定の値で誤差関数を確認したいだけなら、引数に数値リテラルをそのまま渡します。
=ERF.PRECISE(0.5)
=ERF.PRECISE(1.96)
=ERF.PRECISE(-1)3つ目の例のように、負の値も渡せます。誤差関数は奇関数なので、ERF.PRECISE(-1) は約 -0.8427007929 を返します。「絶対値は同じで符号が反転する」と覚えておくと便利です。
セル参照を使う場合
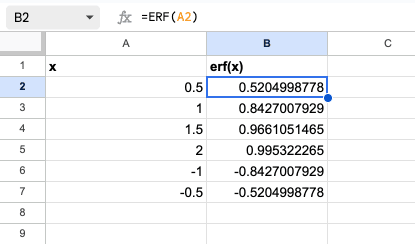
実務では、別セルに入力した値を引数として参照する形が一般的です。A列に x の値を並べて、B列で誤差関数の値を一括計算するような使い方です。
| A | B | |
|---|---|---|
| 1 | x | erf(x) |
| 2 | 0 | =ERF.PRECISE(A2) |
| 3 | 0.5 | =ERF.PRECISE(A3) |
| 4 | 1 | =ERF.PRECISE(A4) |
| 5 | 1.5 | =ERF.PRECISE(A5) |
| 6 | 2 | =ERF.PRECISE(A6) |
B2セルに =ERF.PRECISE(A2) と入力したら、あとは下方向にドラッグコピーするだけです。表計算らしいシンプルな使い方ができます。
!_images/spreadsheet-erf-precise-function/02_formula_erf-precise-basic.png
ERF関数とERF.PRECISEの違い
ここがこの記事のメインです。ERF と ERF.PRECISE の違いを正しく理解しておくと、関数選びで迷わなくなります。
引数の数と積分の下限
最大の違いは「引数の数」と「積分の下限がどう決まるか」です。
=ERF(lower_bound, [upper_bound]) ← ERFは引数1〜2個
=ERF.PRECISE(x) ← ERF.PRECISEは引数1個のみERF 関数は引数を2つ取れます。第1引数に下限、第2引数(省略可)に上限を指定するので、「下限 a から上限 b まで」を任意の区間で計算できます。
一方の ERF.PRECISE は引数が1つだけで、積分の下限は 常に 0 に固定 です。引数で渡せるのは上限値のみで、シンプルである代わりに自由区間の計算はできません。
「ERF(x) = ERF.PRECISE(x)」という等価性
ここがいちばん混乱しやすいポイントです。実は ERF 関数の上限を省略した場合の戻り値と、ERF.PRECISE の戻り値は完全に等価 です。
=ERF(1) → 0.8427007929
=ERF.PRECISE(1) → 0.8427007929
=ERF(0.745) → 0.7079289200
=ERF.PRECISE(0.745) → 0.7079289200なぜこうなるかというと、ERF(x) は上限を省略した場合「下限を 0、上限を x」として扱う仕様だからです。これは ERF.PRECISE(x) の定義(下限 0、上限 x)とまったく同じです。引数を1つだけ渡す限り、両関数は数学的にも実装的にも同じ計算をしています。
どちらを使うべきかの判断基準
「等価ならどっちでもいい」と思うかもしれませんが、ケースによって向き不向きがあります。判断のフローはざっくり次のとおりです。
- 積分区間の下限を 0 以外に指定したい場合 →
ERF関数を使う(引数2つ版) - 下限が 0 で固定でよい場合 → どちらでも可。読みやすさ重視なら
ERF.PRECISE - Excel 2010以降との互換性を重視する場合 →
ERF.PRECISEを選ぶと意図が明確 - 古いExcel(2007以前)との互換性が必要な場合 →
ERFを使う
「下限 0 から x までの誤差関数を取りたい」というケースでは ERF.PRECISE をおすすめします。引数が1つだけと明確なので、後からシートを見返したときに「この ERF の第2引数、なぜ省略してあるんだっけ?」と悩まずに済むからです。
誤差関数ファミリー4関数を比較する
スプレッドシートの誤差関数には、ERF と ERF.PRECISE のほかに、補完誤差関数の ERFC と ERFC.PRECISE があります。4関数の関係を整理しておきましょう。
ERF / ERF.PRECISE / ERFC / ERFC.PRECISEの比較表
| 関数名 | 引数の数 | 積分下限 | 積分上限 | 積分方向 | Excel互換 |
|---|---|---|---|---|---|
ERF | 1〜2個 | 指定した下限値(省略時は0) | 上限値(省略時は下限値) | 自由区間 | あり |
ERF.PRECISE | 1個 | 0 に固定 | 引数の値 | 0〜x 固定 | Excel 2010以降 |
ERFC | 1個 | 引数の値 | ∞ | x〜∞ 固定 | あり |
ERFC.PRECISE | 1個 | 引数の値 | ∞ | x〜∞ 固定 | Excel 2010以降 |
ERFC は補完誤差関数と呼ばれ、ERF の「残り部分」を計算します。具体的には次の関係が成り立ちます。
ERFC.PRECISE(x) = 1 − ERF.PRECISE(x)=ERF.PRECISE(1) が約 0.8427 なら、=ERFC.PRECISE(1) は約 0.1573 になります。「事象が起こる確率」と「起こらない確率」のような相補関係をイメージするとわかりやすいです。
「PRECISE」という名前の意味
「PRECISE」と聞くと「精度が高い」と思ってしまいますが、これは少し違います。.PRECISE はExcel 2010で多くの関数の精度を改善したとき、命名規則を統一するために付けられたサフィックスです。
つまり ERF.PRECISE は「ERFより精度が高い新バージョン」ではなく、「精度改善シリーズの一環として引数を整理した別関数」という位置づけです。引数を1つに固定したことで「この関数は 0 から x までの積分を返す」という挙動が明確になり、誤読を防げます。それが PRECISE 関数群の本来の狙いです。
実際、ERF(x) と ERF.PRECISE(x) の戻り値は小数点以下まで完全に一致するので、「どちらの方が値が正確か」という比較自体が意味を持ちません。
ERF.PRECISEの実務活用パターン
引数1つのシンプルな関数ですが、組み合わせ次第で実務にしっかり使えます。代表的なパターンを2つ紹介します。
正規分布の確率を計算する
誤差関数は正規分布の累積分布関数 Φ(x) と次の関係で結ばれています。
Φ(x) = (1/2) × (1 + erf(x / √2))標準正規分布で「平均から x 標準偏差以内に収まる確率」を求めるとき、誤差関数を使えます。スプレッドシートで書くなら次のような数式です。
=0.5 * (1 + ERF.PRECISE(A2 / SQRT(2)))!_images/spreadsheet-erf-precise-function/04_result_erf-precise-norm.png
A2 に「2」を入れれば、平均±2σ以内に収まる確率(約 0.9772)が返ります。NORM.S.DIST 関数でも同じ値を出せますが、誤差関数の定義から手で組み立てたい場面ではこの形が便利です。
品質管理での不良率計算
製造業の品質管理で「規格外れになる確率」を求めるときにも使えます。たとえば製品の寸法が平均 10mm、標準偏差 0.1mm の正規分布に従い、規格幅が ±0.3mm(9.7〜10.3mm)のとき、規格内に収まる確率は次のように計算できます。
=ERF.PRECISE(0.3 / (0.1 * SQRT(2)))これは約 0.9973 を返し、規格外れ率は 1 − 0.9973 = 0.0027(約 0.27%)とわかります。ERFC.PRECISE を使えば不良率を直接計算することも可能です。
=ERFC.PRECISE(0.3 / (0.1 * SQRT(2)))エラーが出たときの対処法
ERF.PRECISE はシンプルな関数ですが、引数の渡し方を間違えるとエラーになります。代表的な2つを押さえておきましょう。
#VALUE!エラーの原因と解決策
原因: 引数に数値以外(文字列、日付の表記ミス、空白セルへの誤参照など)を渡している。
=ERF.PRECISE("一") → #VALUE!
=ERF.PRECISE(A1) → A1が空白や文字列だと #VALUE!解決策: 引数が必ず数値になっていることを確認します。セル参照の場合は =ISNUMBER(A1) でTRUEが返るかチェックしてみてください。文字列で「1」と入っているなら、=ERF.PRECISE(VALUE(A1)) のように VALUE 関数で変換するのも手です。
#NUM!エラーの原因と解決策
原因: 極端に大きな絶対値を渡したとき、内部計算でオーバーフローするケースがあります。実用範囲内ではほぼ発生しません。
解決策: 引数の絶対値が大きすぎないか確認します。誤差関数は |x| ≥ 4 程度で戻り値がほぼ ±1 に収束します。それ以上の値を渡す必要があるか、業務文脈で見直してみてください。
まとめ
ERF.PRECISE 関数は、引数1つのシンプルな誤差関数です。ERF 関数の上限省略バージョンと数学的に等価で、「下限 0 から x までの誤差関数を取りたい」というシンプルなニーズにぴったり収まります。
ポイントを振り返っておきましょう。
- 構文は
=ERF.PRECISE(x)、引数は 上限値1つだけ - 積分の下限は 0 に固定、自由区間が必要なら
ERFを使う ERF(x)とERF.PRECISE(x)は 完全に等価(小数点以下まで一致)PRECISEは「精度が高い」という意味ではなく、Excel 2010の命名統一によるサフィックス- 補完誤差関数
ERFC.PRECISE(x) = 1 − ERF.PRECISE(x)と組み合わせて確率計算に使える
「下限を自由に指定したい」という場面では ERF 関数の出番です。両者の使い分けや ERF 関数のより詳しい使い方は、ペア記事の スプレッドシートのERF関数の使い方|誤差関数(Error Function)を解説 で解説しています。合わせて読むと誤差関数ファミリー全体を一気に整理できます。
統計・品質管理・工学計算で誤差関数が必要になったら、まずは ERF.PRECISE をシンプルに使ってみてください。下限を変えたくなったら ERF に切り替える。この流れを覚えておけば、関数選びで迷うことはなくなります。
{kind=link}
{kind=link}