スプレッドシートで英語の人名や地名を管理していると、表記がバラバラで困ることってありますよね。「john smith」と「JOHN SMITH」が混在していると、一覧表の見栄えも整いませんし、送付状やメール本文にそのまま流し込むと先方に失礼な印象を与えてしまいます。
かといって、数百件・数千件のデータを1件ずつ手直しするのは現実的ではありません。そんなときに頼りになるのが PROPER 関数です。各単語の先頭だけを大文字に変換し、それ以外を小文字にそろえてくれます。この記事では、スプレッドシートの PROPER 関数の基本から、意外な落とし穴、実務で使えるクレンジング応用までを、同僚に教える感覚でわかりやすく解説していきます。
PROPER関数とは?スプレッドシートで先頭だけ大文字に変換する基本
PROPER 関数は、文字列に含まれる各単語の先頭文字だけを大文字に変換する関数です。それ以外のアルファベットはすべて小文字になります。
読み方・語源
読み方は「プロパー」です。英語の「proper(適切な・正式な)」が由来になっています。人名や地名を「正式な表記」に整えるイメージですね。「John Smith」のように、固有名詞らしい体裁にそろえてくれる関数だと覚えておけば十分です。
たとえば「john smith」を渡すと「John Smith」が返ってきます。日本語や数字、記号はそのまま変わりません。半角アルファベットだけをピンポイントで整えてくれるのがポイントです。
構文と引数
PROPER 関数の構文はとてもシンプルです。
=PROPER(text)
引数はひとつだけです。
| 引数 | 必須/任意 | 説明 |
|---|---|---|
| text | 必須 | 先頭を大文字に変換したい文字列またはセル参照 |
引数にセル参照を指定するのが一般的です。直接文字列を入れる場合は =PROPER("hello world") のようにダブルクォーテーションで囲みます。
UPPER関数やLOWER関数と同じく引数1つだけなので、覚えることはほとんどありません。
基本的な使用例
実際の動きを見てみましょう。A列に入力された文字列に対して、B列で PROPER 関数を使います。
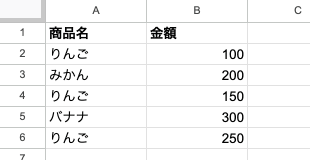
| セル | 入力値 | 数式 | 結果 |
|---|---|---|---|
| B2 | john smith | =PROPER(A2) | John Smith |
| B3 | GOOGLE SHEETS | =PROPER(A3) | Google Sheets |
| B4 | new york city | =PROPER(A4) | New York City |
| B5 | 東京office | =PROPER(A5) | 東京Office |
| B6 | (空セル) | =PROPER(A6) | (空文字列) |
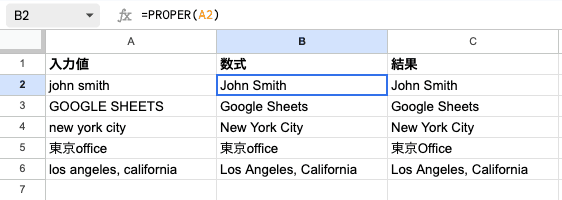
注目してほしいのは B3 の結果です。「GOOGLE SHEETS」のようにすべて大文字の文字列でも、先頭だけが大文字になり、残りはすべて小文字に変換されます。「先頭以外は強制的に小文字にする」という点が、PROPER の大事な性質です。
B5 のように日本語と英字が混在していても問題ありません。日本語の「東京」はそのまま残り、英字の「office」だけが「Office」に変換されます。
B6 のように空のセルを渡した場合は空文字列が返ります。エラーにはならないため、ARRAYFORMULA で広い範囲にまとめて適用しても安心です。

PROPER関数の使い方|実務で役立つ4つの変換パターン
基本がわかったところで、実務でよく使う4つの場面を紹介します。コピーしてすぐに使えるパターンばかりなので、ぜひ手元のデータで試してみてください。
英語の人名・地名を正規化する
顧客リストや住所録で、英語の人名・地名の表記がバラバラになっていませんか? PROPER 関数で一括変換しましょう。
たとえば、A列に人名が入っているとします。B2 に次の数式を入れてください。
=PROPER(A2)
| A列(入力) | B列(変換後) |
|---|---|
| john smith | John Smith |
| MARY JOHNSON | Mary Johnson |
| robert brown | Robert Brown |
| ANNA KIM | Anna Kim |
すべて「先頭大文字+残り小文字」の形式に統一されます。B2 をコピーして下方向に貼り付ければ、一覧全体を一気に整えられますよ。
請求書や送付状で相手の名前を正しく表記したいときにも便利です。差し込み印刷の前処理として組み込んでおくと、表記揺れによる先方からのクレームを防げます。
カンマ・ハイフン区切りの文字列を整える
PROPER 関数は、スペースだけでなくカンマやハイフンの後も「単語の区切り」として扱います。区切り文字を含む文字列でも、各単語の先頭がきちんと大文字になります。
=PROPER(A2)
| A列(入力) | B列(変換後) |
|---|---|
| los angeles, california | Los Angeles, California |
| new-york | New-York |
| o’brien | O’Brien |
| smith, john | Smith, John |
アポストロフィの直後も大文字になるため、「o’brien」が「O’Brien」と正しく変換されます。住所や複合姓の整形にそのまま使えますね。
ただし、英語の所有格(john's book)にそのまま使うと「John’S Book」のように「S」まで大文字になってしまいます。所有格を扱う場合は後述の SUBSTITUTE 補正で 's を 's に戻すなど、ひと工夫加えましょう。
TRIM関数と組み合わせてデータクレンジング
外部システムから取り込んだデータには、余分なスペースが紛れ込んでいることがよくあります。PROPER 関数とTRIM関数を組み合わせれば、スペース除去と先頭大文字変換を一度に処理できます。
=PROPER(TRIM(A2))
| A列(入力) | B列(変換後) |
|---|---|
| john smith | John Smith |
| MARY JOHNSON | Mary Johnson |
| robert brown | Robert Brown |
先に TRIM 関数で余分なスペースを除去してから、PROPER 関数で先頭大文字に変換する流れです。名前のクレンジング処理として定番のパターンなので、覚えておくと重宝しますよ。
SUBSTITUTE関数で全角スペース・特殊区切りに対応する
TRIM 関数だけだと、全角スペースは除去されません。全角と半角が混在している CSV を扱う場合は、SUBSTITUTE関数を組み合わせて、先に全角スペースを半角に置換してから TRIM と PROPER をかけます。
=PROPER(TRIM(SUBSTITUTE(A2," "," ")))
| A列(入力) | B列(変換後) |
|---|---|
| john smith | John Smith |
| MARY JOHNSON | Mary Johnson |
| ANNA KIM | Anna Kim |
ちょっとむずかしく見えますが、やっていることはシンプルです。「全角スペースを半角に直す」→「連続スペースを1つにまとめる」→「先頭大文字にそろえる」を1つの数式で連続処理しているだけです。
タブ区切りや改行で崩れたデータの場合は、SUBSTITUTE の対象文字を CHAR(9)(タブ)や CHAR(10)(改行)に置き換えれば応用できます。
PROPERの意外な動作と注意点
PROPER 関数はシンプルですが、知らないと意図しない結果になるクセがいくつかあります。実務で使う前に必ずチェックしておきましょう。
日本語・全角英字には効果がない
PROPER 関数が変換するのは半角アルファベットだけです。日本語のひらがな・カタカナ・漢字には何も起きません。
=PROPER("こんにちは世界") → こんにちは世界
日本語だけのセルに使っても、そのまま返ってくるだけです。エラーにはならないので、英語と日本語が混在するデータに一括適用しても問題ありません。
また、全角英字(abc、ABC など)も変換されません。Google スプレッドシートには Excel の ASC 関数(全角→半角変換)が存在しないため、全角英字を含むデータは先にSUBSTITUTE関数で半角に置換してから PROPER 関数を使いましょう。
たとえば 1文字ずつ全角→半角を当てる対応は手間なので、データ取り込み段階で「半角英数のみ」と決めてしまうのが現実的です。
数字・記号の後の文字も大文字になる
PROPER 関数は「アルファベット以外の文字」の直後を「単語の先頭」とみなします。そのため、数字や記号の直後にあるアルファベットも大文字に変換されます。
| 入力値 | 結果 | 解説 |
|---|---|---|
| 2nd floor | 2Nd Floor | 数字の直後の n が大文字に |
| room#3a | Room#3A | # と 3 の直後が大文字に |
| hello/world | Hello/World | スラッシュも区切りと判断 |
| john’s book | John’S Book | アポストロフィの直後の s が大文字に |
| ハイフンの直後の m が大文字に |
「2nd」が「2Nd」になるのは、意図した結果ではないことが多いですよね。この動作を知らずに使うと、住所や所有格のデータが崩れてしまいます。

TIP
数字・記号を含む文字列に PROPER 関数を使うときは、結果を必ずサンプルで確認しましょう。意図しない変換があった場合は、後段で SUBSTITUTE 関数で個別に戻すのが確実です。たとえば
=SUBSTITUTE(PROPER(A2),"2Nd","2nd")のように対症療法的に置換します。
McDonald・iPhone・USAなど固有名詞は補正が必要
PROPER 関数は「各単語の先頭を大文字、残りを小文字」にする関数です。独自の大文字ルールを持つ固有名詞には対応できません。
| 入力値 | PROPERの結果 | 期待値 |
|---|---|---|
| mcdonald | Mcdonald | McDonald |
| iphone | Iphone | iPhone |
| usa | Usa | USA |
| jpmorgan | Jpmorgan | JPMorgan |
| ipad | Ipad | iPad |
「McDonald」の「D」や「iPhone」の「P」は、単語の途中にある大文字です。PROPER 関数はこれを小文字に変えてしまいます。「USA」「JPMorgan」のような略語混じりの社名も同様です。
こうしたケースでは、PROPER 関数の後に SUBSTITUTE 関数で個別に補正しましょう。
=SUBSTITUTE(SUBSTITUTE(PROPER(A2),"Mcdonald","McDonald"),"Iphone","iPhone")
頻出する固有名詞が10語以上ある場合は、置換ペアを別シートに辞書として持たせ、REGEXREPLACE や LAMBDA で順番に当てていく方法もあります。件数が少なければ手動修正のほうが早い場面も多いので、PROPER は「おおまかに整える」ツールとして使い、細かい例外は別途対応する割り切りがおすすめです。
UPPER・LOWER・PROPERの違いと使い分け
スプレッドシートには、文字の大文字・小文字を操作する関数が3つあります。PROPER 関数と似た機能を持つUPPER関数、LOWER関数との違いを整理しておきましょう。
3関数の比較表
| 関数 | 機能 | 入力例 | 出力例 | 主な用途 |
|---|---|---|---|---|
| UPPER | すべて大文字に変換 | hello world | HELLO WORLD | 製品コード、国コード、SKU |
| LOWER | すべて小文字に変換 | Hello World | hello world | メールアドレス、URL、ID |
| PROPER | 各単語の先頭だけ大文字に変換 | hello world | Hello World | 人名、都市名、社名(注意点あり) |
構文はどれも同じ形です。=UPPER(text) =LOWER(text) =PROPER(text) のように、引数はひとつだけです。覚えてしまえば3関数まとめて使い分けられますよ。
どれを使うか迷ったときの判断フロー
3つの関数を使い分けるポイントは「最終的にどう表示したいか」です。次の基準で判断してみてください。
- 全部大文字にしたい → UPPER関数(例: 製品コード、国コード、部署コード)
- 全部小文字にしたい → LOWER関数(例: メールアドレス、URL、SNSアカウント)
- 先頭だけ大文字にしたい → PROPER 関数(例: 人名、都市名の表記統一)
- 固有名詞の独自ルールを残したい → PROPER 後に SUBSTITUTE で補正、もしくは手動修正
迷ったら、まずデータの用途を考えてみてください。コード類は大文字統一、メールアドレスや URL は小文字統一が一般的です。人名や地名は PROPER が便利ですが、固有名詞のクセには気をつけましょう。
ARRAYFORMULA・MAP/LAMBDAでの列一括変換テクニック
データが数百行・数千行あると、数式をコピーするのも手間ですよね。スプレッドシートには配列対応のテクニックが2系統あるので、好きなほうを選んでください。
ARRAYFORMULAで列全体を一括変換
定番は ARRAYFORMULA です。B2 セルに次の数式を入力してください。
=ARRAYFORMULA(PROPER(A2:A))
これだけで、A2 以降のすべての行に対して PROPER 関数が適用されます。A列にデータを追加すると、B列にも自動で変換結果が表示されます。
ちょっとむずかしく見えますが、やっていることはシンプルです。「PROPER 関数を配列(複数セル)にまとめて適用する」だけです。
ひとつ注意点があります。ARRAYFORMULA を使っている場合、B列の途中にデータを手入力するとエラーになります。B列はすべて ARRAYFORMULA に任せて、手入力しないようにしてください。
IF と組み合わせて空白行を除外する
空白行に「(空欄)」と表示されるのが気になる場合は、IF 関数と組み合わせましょう。
=ARRAYFORMULA(IF(A2:A="","",PROPER(A2:A)))
A列が空白のときは B列も空白にする、という条件を加えた数式です。シートの見た目がスッキリするのでおすすめですよ。
TRIM 関数との組み合わせも ARRAYFORMULA で一括処理できます。
=ARRAYFORMULA(IF(A2:A="","",PROPER(TRIM(A2:A))))
人名リストの一括クレンジングなど、大量データの前処理にぜひ活用してみてください。
MAP/LAMBDA で代替する書き方
Google スプレッドシートには 2022 年以降、LAMBDA 系の関数(MAP、BYROW、BYCOL など)が追加されました。MAP を使えば ARRAYFORMULA と同じことをよりシンプルに書けます。
=MAP(A2:A10, LAMBDA(v, PROPER(v)))
v は各セルの値を表す仮の変数名で、自由に名前を付けられます。やりたい処理が複雑になっても、LAMBDA 内に書き足していけるのが利点です。たとえば TRIM と PROPER を組み合わせるなら次のように書きます。
=MAP(A2:A10, LAMBDA(v, IF(v="", "", PROPER(TRIM(v)))))
固定範囲(A2:A10)を指定する書き方になるため、行数が読めない場合は ARRAYFORMULA のほうが向いています。一方で、複数列を別々の処理にしたい・処理を後で拡張したいといった場合は MAP のほうが読みやすくなります。
よくある質問
PROPER 関数を使うときに気になるポイントをまとめました。
Q. 元のセルのデータは書き換わりますか?
いいえ、書き換わりません。PROPER 関数は別のセルに変換結果を返します。元データを置き換えたい場合は、変換結果の列をコピーして、元の列に「値のみ貼り付け」(Ctrl + Shift + V)してください。
Q. 日本語が含まれていても使えますか?
はい、使えます。PROPER 関数は半角アルファベットだけを変換します。日本語・数字・記号はそのまま残るので、「東京office」のような混在テキストでも安心です。
Q. 全角英字(abc)も変換されますか?
残念ながら、全角英字は変換されません。Google スプレッドシートには全角→半角変換の ASC 関数がないため、先にSUBSTITUTE関数で半角に置換してから PROPER 関数を適用してください。CSV 取り込み段階で「半角英数のみ」とルール化しておくのが現実的です。
Q. Excel の PROPER 関数と違いはありますか?
構文も動作も完全に同じです。スプレッドシートで作った数式は Excel でもそのまま動きます。互換性を気にせず使って大丈夫ですよ。
Q. 空のセルを参照するとエラーになりますか?
エラーにはなりません。空のセルを渡すと空文字列が返ります。大量のデータに ARRAYFORMULA で一括適用しても、空白行でエラーが出る心配はありません。
Q. ARRAYFORMULA と MAP/LAMBDA はどちらが速いですか?
数百〜数千行程度なら、体感差はほぼありません。数万行を超えるような巨大データでは、ARRAYFORMULA のほうがやや軽い傾向があります。可読性を重視するなら MAP/LAMBDA、対応行が読めない場合は ARRAYFORMULA、と使い分けるのがおすすめです。
まとめ
PROPER 関数は、各単語の先頭だけを大文字に変換できるシンプルな関数です。この記事のポイントを振り返っておきましょう。
- 構文は
=PROPER(text)で引数はひとつだけ - 半角アルファベットのみ変換される(日本語・数字・全角英字はそのまま)
- 英語の人名・地名・住所の表記統一に便利
- 数字や記号(’、#、/、- など)の直後も「単語の区切り」として扱われる点に注意
- McDonald・iPhone・USA など固有名詞の独自ルールには対応できない(SUBSTITUTE で補正)
- 全角スペース混じりのデータは SUBSTITUTE → TRIM → PROPER の順で前処理する
- UPPER関数(全大文字)・LOWER関数(全小文字)との使い分けがポイント
- ARRAYFORMULA か MAP/LAMBDA を組み合わせれば列全体を一括変換できる
- TRIM関数との組み合わせでスペース除去も同時に処理可能
データの正規化をさらに進めたい方は、UPPER関数やLOWER関数、SUBSTITUTE関数もあわせてチェックしてみてください。大文字・小文字変換や特定文字列の置換にも役立ちます。PROPER をクレンジング処理の一部として組み込めば、毎月の名簿整理が一段とラクになりますよ。